A practical approach to building a network CI/CD pipeline
Continuous integration and continuous deployment (CI/CD) is the practice of automatically packaging, testing, and deploying code, generally in small increments. This modern DevOps practice has made software development agile and reliable, and it holds the same promise for networking as more environments transition to the infrastructure-as-code (IaC) model.
In this post, we’ll outline a practical network CI/CD pipeline similar to the ones we’ve helped build for our customers and other Batfish users. A demo of this pipeline is on YouTube and the code is on GitHub. Reading our earlier blogs isn’t a prerequisite for reading this one, but if you’re curious about basic concepts behind network validation and CI/CD, you may find it useful to check out our posts on validation types (including verification versus testing) and CI/CD pipeline structure options.
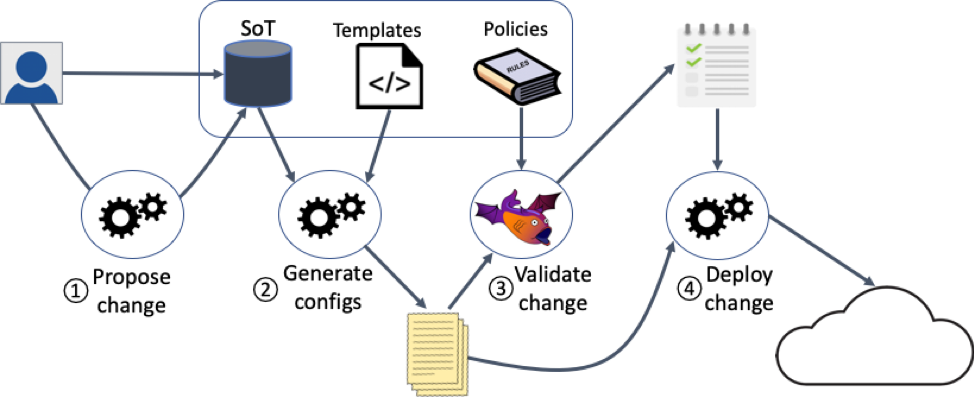
Let’s get started. Our CI/CD pipeline, shown in the figure above, has three main inputs:
- Source of Truth (SoT): The SoT stores your network configuration constants such as IP addresses, NTP servers, VLANs, and DNS servers. It also stores behavior related to these constants, such as list of flows that should be permitted or denied, and zones within the network that are allowed or disallowed access from the internet. You can have multiple SoTs in a variety of formats, as long as there is only one authoritative source for any piece of information. You can capture the SoT in text files, which allows it to be stored in Git, or in a database like NetBox. Our demo uses multiple YAML files—one for the base system configuration, and one for packet filtering information to generate firewall zone policies via Capirca, a multi-platform access control list (ACL) generation system.
- Configuration templates: The SoT is combined with configuration templates to build network config files. It helps to separate the boilerplate configuration structure into multiple templates that can generate the config files when combined with the SoT, enabling maximum re-use across devices. Our demo uses multiple Jinja2 templates for each device role.
- Policies: These define good things that should happen in the network — for example, all border gateway protocol (BGP) sessions should come up or all pairs of routers should be able to communicate — or bad things that should never happen, like packets from the Internet being able to communicate with a router. Our demo uses a combination of Ansible playbooks and pytest files to express policy. (Using both isn’t necessary. We did that to illustrate the options.)
The demo pipeline combines these inputs into a four-step workflow:
- Propose change: The workflow begins with you or another network engineer/operator proposing a change to the network, or by the system initiating a script in response to, say, a ServiceNow ticket. Whichever method you choose, proposing the change entails modifying either the SoT or the templates.You should consider scripting all common network changes, such as adding a new flow to the packet filters or bringing down a device for maintenance. The scripting approach is helpful for not only consistency and speed but also because it allows you to evolve the SoT format without having to modify the mechanism by which changes are proposed. Our demo uses Ansible playbooks as change scripts for changing packet filters at the border firewall and for provisioning new leaf routers in the fabric.For any changes you don’t initiate using scripts, you can modify the SoT or templates manually. These scripted or manual modifications are committing to a new Git branch. This commit triggers the pipeline file, which in turn orchestrates the successive workflow steps below as long as the prior one hasn’t failed.
- Generate configs: The second step generates config files from the templates and the SoT. This can be as simple as calling the render function on the template, or it can be more involved with custom data manipulation. Our demo uses custom logic to convert Capirca definitions in the SoT to device specific ACL syntax, and then merges that with the templates we created using jinja2.
- Validate change: The third step examines the generated configs and policies to determine which policies pass or fail. Our demo uses Batfish for validation.
- Deploy change: This final step occurs only after the validation step judges that no critical policy is failing and, optionally, you conduct a manual review. Our demo does not include deployment scripts (or network devices), but you can create these based on systems like Ansible, Nornir, or NAPALM.
Tips and tricks
So far, we’ve described the optimal operations of our demo pipeline from a high-level view. The reality, of course, is that you’ll probably have to resolve additional setup issues as they arise. By looking at our code, you can see many of the issues we encountered, warts and all. Let’s list a few of them here that aren’t specific to our network, and tell you how we suggest you work around them if they apply to you.
- Multiple SoT formats. Using multiple SoT formats can be a useful pattern. Because all SoT information isn’t required to be in the same format or database, you can store different elements of your configuration in whatever method they’re best suited to. For example, you might use separate databases to store NTP server and BGP peers.As mentioned earlier, our demo pipeline uses two SoT formats: Capirca definitions for ACLs and firewalls rules, and a YAML-based format for all other data. We chose these formats for convenience and flexibility. Using Capirca meant that we didn’t have to write vendor-specific configuration templates for packet filters and we can more easily swap out our firewall vendor if needed.Using multiple SoT formats does complicate the configuration generation script slightly, because you have the additional step of merging them together. In this case, it means running Capirca first and then merging its results with what was produced via the jinja2 rendering. For our demo pipeline, we deemed this additional step to be a worthwhile tradeoff given the advantages of using Capirca.
- Local Gitlab setup. If you’re using Gitlab CI, it helps when prototyping your pipeline to run the GitLab community edition container locally with the Shell executor as the runner. This enables rapid iteration and will free you from worrying about permissions and remote environment setup for the runner. This setup is fairly easy, as our instructions If any port conflicts arise, as they commonly do with this method, Gitlab has instructions for resolving those.
- Debugging the pipeline. Debugging a CI/CD pipeline is not as straightforward as debugging locally running code, but it is not difficult either with the right approach. Two useful tools, available in all CI systems, are the pipeline output and job artifacts. The pipeline output shows the stdout and stderr of the scripts that run in the pipeline. However, not everything you want to see after the CI pipeline has run is suitable for printing to stdout. For example, you might want to see the configs generated in Step 2 above in order to debug the generation or validation scripts. That’s where job artifacts come in. These are files and folders created when the pipeline runs and saved for later viewing. Our demo pipeline saves generated configs as artifacts, but you can add anything you need to the artifact set. GitLab provides instructions on creating and viewing artifacts here.
Summary
Hopefully we’ve convinced you that a CI/CD pipeline is within reach for your network, and that our related resources (code, demo) are helpful as you embark on that journey.
The goal of this post was to lay down the network pipeline CI/CD basics. Stay-tuned for future discussions focused on creating network policies for CI/CD and integrating CI/CD into your existing “brownfield” network.
We love hearing about your experience. For any questions or comments, reach us on Batfish Slack.